
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 웹 스터디
- spring reactive
- reactive
- reactor
- 서버운영
- 공유기 서버
- 웹 커리큘럼
- Spring Framework
- ipTIME
- 웹앱
- reactor core
- Spring Batch
- Today
- Total
Hello World
[펌][Apache Kafka] 2. 클러스터 구축하기 본문
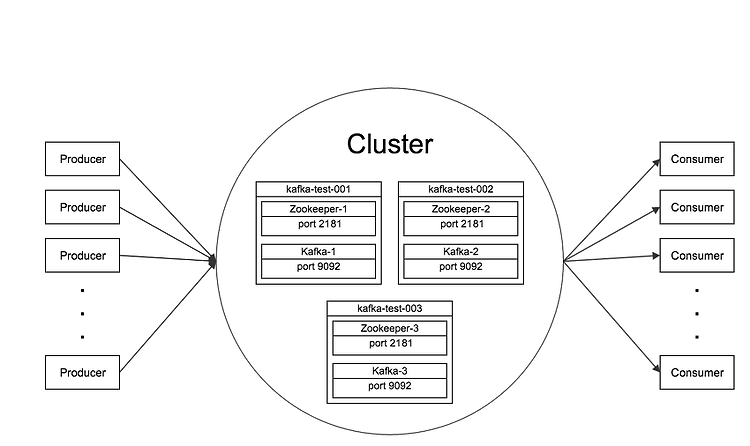
이 글에서는 위의 그림처럼 3개의 인스턴스로 구성된 클러스터를 구축해 본다.
클러스터를 구성하는 kafka-test-001, kafka-test-002, kafka-test-003 인스턴스는 Zookeeper 인스턴스와 Kafaka broker를 하나씩 가지고 있다.
이 글에서는 3대의 VM을 사용하여 클러스터를 구축하는데 만약 1대의 서버에 테스트 용도로 클러스터를 구축할 경우 각 인스턴스의 ID와 사용하는 디렉토리와 포트 번호만 겹치지 않게 설정하면 동일한 방식으로 구축할 수 있다.
Zookeeper 클러스터 구축
Kafka의 대부분의 동작은 Zookeeper와 연계되어 있기 때문에 Zookeeper 없이는 Kafka를 구동할 수 없다. 이 때문에 Kafka 패키지를 받으면 패키지 안에 Zookeeper도 함께 들어있다. 물론 Kafka 패키지 안에 들어있는 Zookeeper 대신 Zookeeper 최신 버전 패키지를 받아서 사용해도 되지만, 패키지 안에 들어있는 Zookeeper는 해당 Kafka 버전과 잘 동작하는 것이 검증된 버전이므로 개인적으로는 패키지 안에 들어있는 Zookeeper의 사용을 권장한다. 그리고 Zookeeper 패키지에 들어있는 sh 파일명과 Kafka 패키지 안에 들어있는 sh 파일명이 다르기 때문에 이 글은 Kafka 패키지에 포함된 Zookeeper를 기준으로 작성하였다.
Zookeeper 설정 및 구동
Kafka 패키지에 기본적으로 포함되어 있는 config/zookeeper.properties 파일은 하나의 Zookeeper 인스턴스를 실행하는데 쓰이는 설정 파일이다. 3개의 인스턴스로 이루어진 클러스터를 구축하기 위해서는 인스턴스 간 통신을 할 때 필요한 설정을 추가해 주어야 한다.
config/zookeeper.properties 파일을 열면 기본적으로 다음의 항목들이 설정되어 있다.
dataDir=/tmp/zookeeper
clientPort=2181
maxClientCnxns=0
해당 설정 파일에 다음의 설정을 추가해 준다.
initLimit=5
syncLimit=2
server.1=kafka-test-001.epicdevs.com:2888:3888
server.2=kafka-test-002.epicdevs.com:2888:3888
server.3=kafka-test-003.epicdevs.com:2888:3888
인스턴스가 3개인 클러스터를 구축할 예정이므로 server.1, server.2, server.3을 설정해 준다. server.#에서 #은 인스턴스의 ID이다. 설정 파일에 대한 상세한 내용은 Zookeeper의 Administrator's Guide를 참조하길 바란다.
설정 파일에 인스턴스들에 대한 정보를 입력했지만, 각 인스턴스들은 설정 파일만 가지고서는 자신의 ID가 무엇인지 알 수 없다. 이 때문에 인스턴스의 ID를dataDir 디렉토리 아래의 myid라는 파일에 명시해 주어야 한다.
예를 들어 1번 인스턴스의 myid 파일에는 1이 입력되어 있어야 하므로 다음의 커맨드를 실행하여 myid 파일을 생성하면 된다.
echo 1 > /tmp/zookeeper/myid
3개의 인스턴스에 모두 각자의 myid를 생성한 뒤 다음의 커맨드를 각 인스턴스에서 실행하면 Zookeeper 클러스터가 구동된다.
bin/zookeeper-server-start.sh config/zookeeper.properties
Kafka 클러스터 구축
Broker 설정 및 구동
Kafka 패키지에 기본적으로 포함되어 있는 config/server.properties는 하나의 Kafka broker를 실행하는데 쓰이는 설정 파일이다. 3개의 broker로 이루어진 클러스터를 구축하기 위해서는 해당 파일의 설정을 변경해 주어야 한다.
Kafka 클러스터 내의 broker 리스트는 Zookeeper가 관리하므로 설정 파일에는 다른 broker에 대한 정보를 입력할 필요 없이 자신의 broker ID만 명시해 주면 된다.
별도의 파일에 인스턴스의 ID를 명시해야 하는 Zookeeper와는 달리 Kafka는 설정 파일의 broker.id라는 항목에 인스턴스의 ID를 아래와 같이 명시하면 된다.
broker.id=1
그리고 Zookeeper와 연동을 위하여 zookeeper.connect라는 항목에 Zookeeper 인스턴스들의 정보를 입력한다.
zookeeper.connect=kafka-test-001.epicdevs.com:2181,kafka-test-002.epicdevs.com:2181,kafka-test-003.epicdevs.com:2181
위의 설정을 모두 마친 뒤 다음의 커맨드를 각 인스턴스에서 실행하면 Kafka 클러스터가 구동된다.
bin/kafka-server-start.sh config/server.properties
실제 운영에서는 디스크에 메시지를 얼마나 오랫동안 유지할지 그리고 얼마나 많이 유지할지에 대한 다음의 설정 또한 중요하다.
프로퍼티 | 기본 값 | 설명 |
log.retention.hours | 168 | 메시지의 수명. 수명이 지나면 메시지가 삭제된다. |
log.retention.bytes | -1 | Partition의 물리적 최대 크기. 크기를 초과하면 디스크에서 메시지가 삭제된다. log.retention.bytes x partition의 수는 topic의 물리적 최대 크기가 된다. 이 값이 -1이면 크기는 무제한으로 설정된다. |
설정 파일에 대한 상세한 내용은 Kafaka 공식 문서의 3.1 Broker Configs를 참조하길 바란다.
Topic 생성하기
클러스터를 구축했으니 이제 topic을 생성해 보자. Partition 20개로 이루어진 test라는 topic을 생성하도록 한다. 클러스터를 구성하는 인스턴스는 3대이므로 replication factor는 3으로 설정한다.
bin/kafka-topics.sh --create --zookeeper kafka-test-001.epicdevs.com:2181 --replication-factor 3 --partitions 20 --topic test
위의 커맨드를 실행하면 아래와 같이 20개의 partition이 생성된 것을 확인할 수 있다. (Kafka 설정 파일의 log.dirs에 명시된 디렉토리에 partition이 생성된다.)

아래의 커맨드를 실행하면 클러스터 내의 topic 리스트를 확인할 수 있다.
bin/kafka-topics.sh --list --zookeeper kafka-test-001.epicdevs.com:2181
아래의 커맨드를 실행하면 특정 topic의 partition과 replica에 대한 상세 정보를 확인할 수 있다.
bin/kafka-topics.sh --describe --zookeeper kafka-test-001.epicdevs.com:2181 --topic test
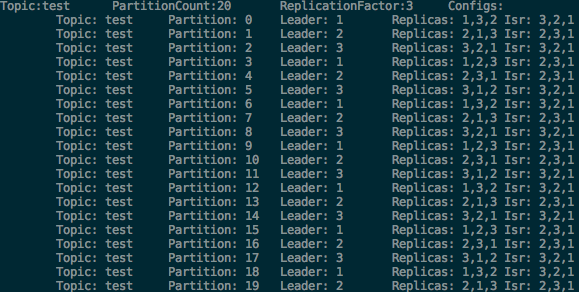
아래의 커맨드를 3번 인스턴스에서 실행하여 3번 broker를 정지시킨 다음 위의 커맨드를 실행하면 3번 broker가 leader이던 partition들이 fail over되면서 leader가 변경된 것을 확인할 수 있다.
bin/kafka-server-stop.sh
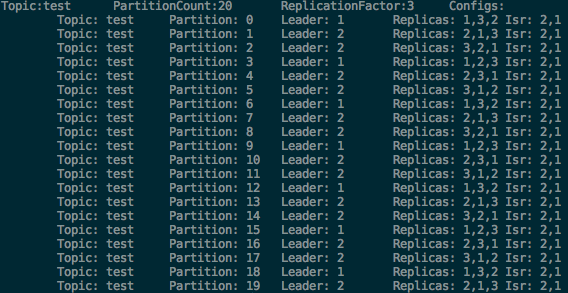
Isr(in-sync replica)은 현재 정상적으로 구동되고 있는 replica의 목록이다. 현재 3번 broker가 정지되었기 때문에 1번과 2번 broker만 in-sync 상태인 것을 확인할 수 있다.
(위 상황에서 3번 broker가 다시 복구되어 클러스터에 합류할 경우 3번 broker는 모든 partition에 대하여 follower가 된다. 즉, 3번 broker는 leader를 맡은 partition이 없는 상황이 되어 부하가 적절하게 분산되지 않는 현상이 발생한다. 이 때 kafka-preferred-replica-election.sh를 사용하여 3번 broker가 다시 partition들의 leader를 맡도록 할 수 있다. 이에 대한 자세한 사항은 Kafka 공식 문서의 Balancing leadership을 참조하길 바란다.
내용 추가: 2015.03.19
Kafka 0.8.2부터는 broker가 복구된 후 클러스터에 합류할 경우 자동으로 leader가 분배되도록 변경되었다. 이와 관련된 broker 설정은 auto.leader.rebalance.enable인데 0.8.1까지는 이 값이 false였는데 0.8.2부터는 이 값이 true로 변경되었다. 0.8.1까지는 이 값을 true로 설정할 경우 이슈가 있어서 false로 해 둔 것이고 0.8.2부터는 이슈가 해결되어 true로 변경되었다.)
Topic 설정 변경하기
이미 생성된 topic의 partition 수를 늘리거나 설정을 변경하는 것도 kafka-topics.sh를 통해 가능하다.
아래의 커맨드를 실행하면 test의 partition 수가 20에서 40으로 증가한다.
bin/kafka-topics.sh --alter --zookeeper kafka-test-001.epicdevs.com:2181 --topic test --partitions 40
Partition의 수를 늘리는 것 외에도 topic과 관련된 설정을 변경할 수도 있다. 이에 대한 상세한 내용은 Kafaka 공식 문서의 Topic-level configuration을 참조하길 바란다.
Kafka는 현재 topic의 partition 수나 replication factor를 감소시키는 것은 지원하지 않으므로 topic을 처음 생성할 때 이를 주의해야 한다. (kafka-reassign-partitions.sh를 사용하면 replication factor를 증가시킬 수 있다. 상세한 사항은 Kafka 공식 문서의 Increasing replication factor를 참조하길 바란다.)
Topic 자동 생성시 주의할 점
존재하지 않는 topic에 대하여 메시지를 생산하거나 소비할 경우 broker의 설정 값에 따라 topic이 자동으로 생성될 수 있다. 그런데 topic이 자동으로 생성되도록 설정해 두었을 경우 partition의 수와 replica의 수 또한 설정 값을 따르게 된다. 그런데 이 값을 별도로 설정하지 않을 경우 기본 값을 사용하게 되면서 문제가 발생할 수 있다.
기본 설정 그대로 topic을 자동 생성할 경우 1개의 partition과 replica를 가지는 topic이 생성되는데 이 값은 실제 운영에는 적합하지 않다. 따라서 topic을 사용하기 전에 kafka-topics.sh를 통해 적절한 설정 값을 가지는 topic을 미리 생성해 둔다면 이와 같은 실수를 미연에 방지할 수 있다.
위 내용과 관련된 broker의 설정은 다음과 같다.
프로퍼티 | 기본 값 | 설명 |
auto.create.topics.enable | true | Topic을 자동으로 생성할지 여부. |
num.partitions | 1 | Topic을 자동으로 생성할 때 생성할 partition의 수 |
default.replication.factor | 1 | Topic을 자동으로 생성할 때 생성할 replica의 수 |
Producer/Consumer 테스트
Kafka 패키지에는 테스트 용도로 사용할 수 있는 producer와 consumer가 포함되어 있다. 둘을 이용하여 간단하게 메시지를 생산하고 소비해 보자.
메시지 생산하기(Producer)
아래의 커맨드를 입력한 뒤 터미널 창에 키보드로 입력하면 메시지가 생산된다.
bin/kafka-console-producer.sh --broker-list kafka-test-001.epicdevs.com:9092 --topic test
메시지 소비하기(Consumer)
아래의 커맨드를 입력하면 해당 topic의 메시지를 소비한다. 기본적으로 kafka-console-consumer.sh는 실행된 시점 이후에 생산되는 메시지만 소비하기 때문에 from-beginning 옵션을 주어 해당 topic의 맨 처음 메시지부터 소비하도록 하였다.
bin/kafka-console-consumer.sh --zookeeper kafka-test-001.epicdevs.com:2181 --topic test --from-beginning
참고자료
'Back-End > 좋은글' 카테고리의 다른 글
| [펌][Apache Kafka] 5. Zookeeper 트리 분석 (0) | 2016.01.10 |
|---|---|
| [펌][Apache Kafka] 4. 모니터링하기 (0) | 2016.01.10 |
| [펌][Apache Kafka] 3. Producer/Consumer 구현하기 (0) | 2016.01.10 |
| [펌][Apache Kafka] 1. 소개 및 아키텍처 정리 (0) | 2016.01.10 |
| [펌]ELKR (ElasticSearch + Logstash + Kibana + Redis) 를 이용한 로그분석 환경 구축하기 (0) | 2016.01.10 |